This page is not yet available in Deutsch. Showing English version.
Real-World Purview Benchmark: We Tested Microsoft Purview on 89,521 Files

Nobody believes a small Danish company when we say Purview classification does not work for real-world GDPR compliance. So we did something about it: we created a synthetic benchmark dataset that anyone can download and test themselves.
The Dataset
We analyzed over 5 petabytes of real-world data and generated a synthetic dataset that mirrors real unstructured data, without using any actual personal data. The distribution of file types is based on statistical analysis and reflects the typical mix found in enterprise environments.
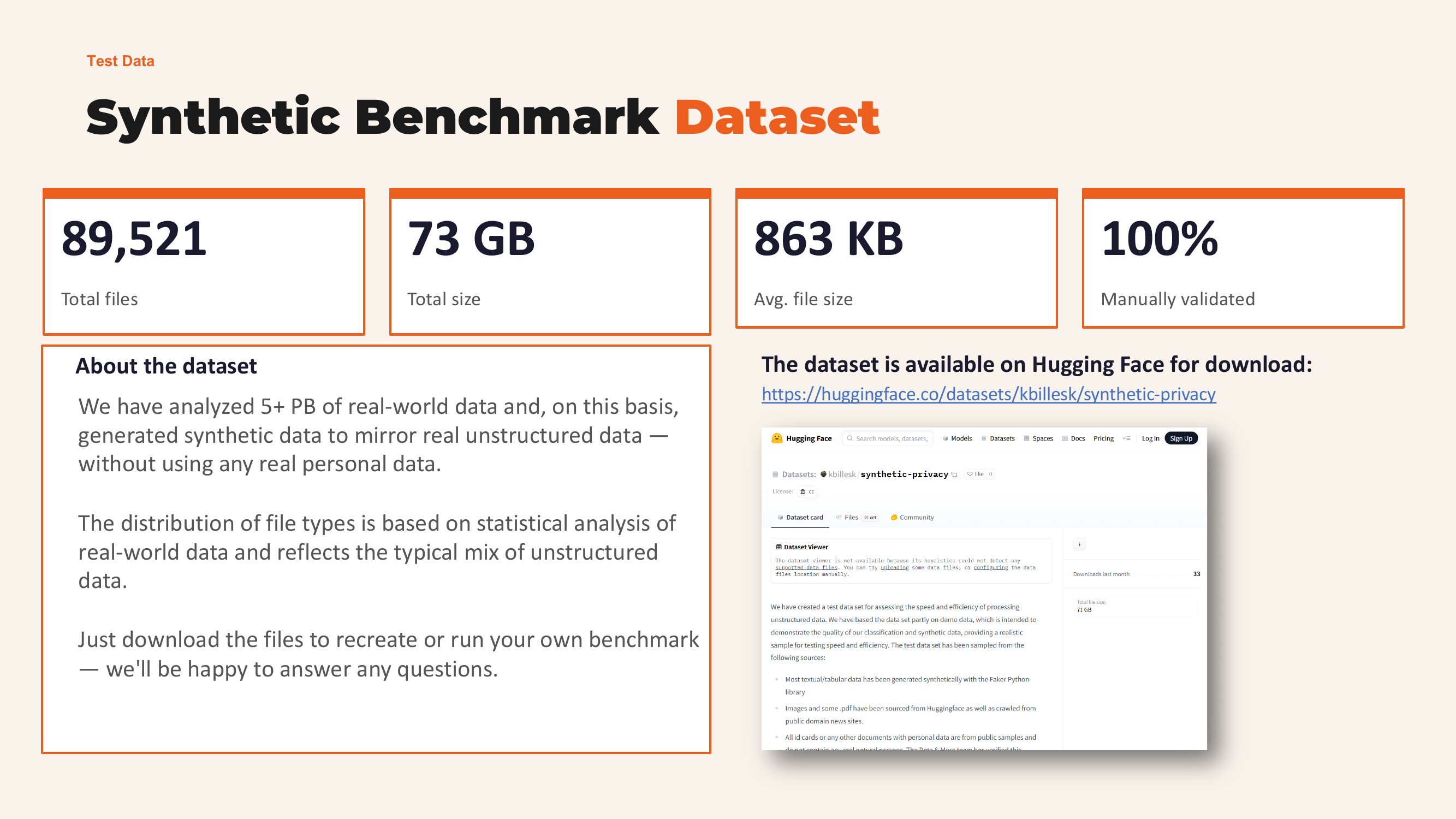
89,521 files total
73 GB total size
863 KB average file size
100% manually validated ground truth
The dataset is available on Hugging Face for anyone to download and reproduce: huggingface.co/datasets/kbillesk/synthetic-privacy
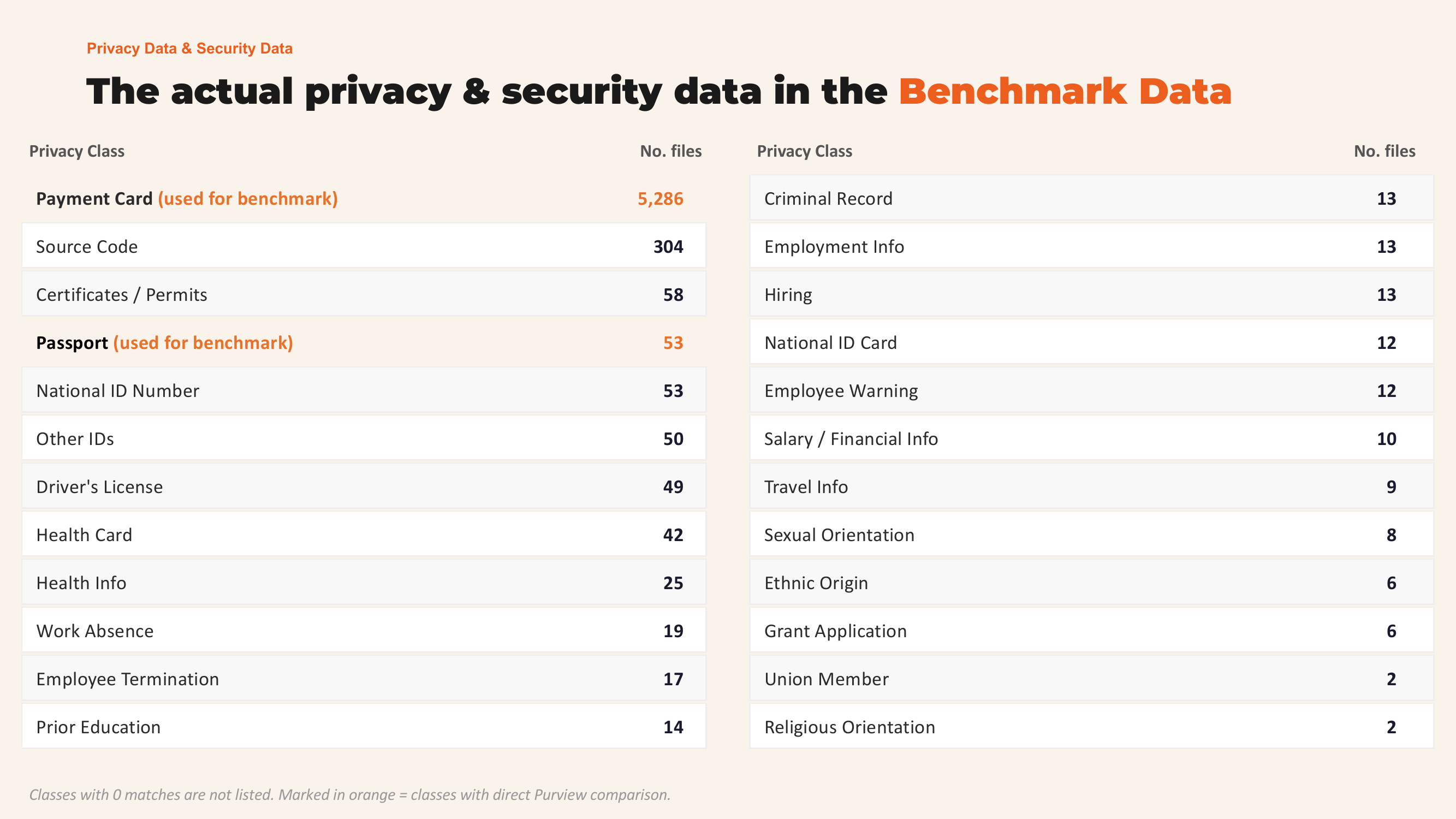
Privacy and Security Data in the Benchmark
The benchmark dataset contains 25 categories of privacy and security data. The two categories used for direct Purview comparison are Payment Card (5,286 files) and Passport (53 files).
Why Classification Matters
Everything in Microsoft Purview depends on correct classification. Sensitivity labels, auto-labeling, Data Loss Prevention (DLP), and retention management all rely on the ability to classify and tag data correctly. If classification fails, every downstream feature fails with it.
Benchmark Results: Passport Classification
We used Purview's out-of-the-box Passport classification (set to medium confidence) and compared it against the known ground truth in our dataset. The data was stored in SharePoint.
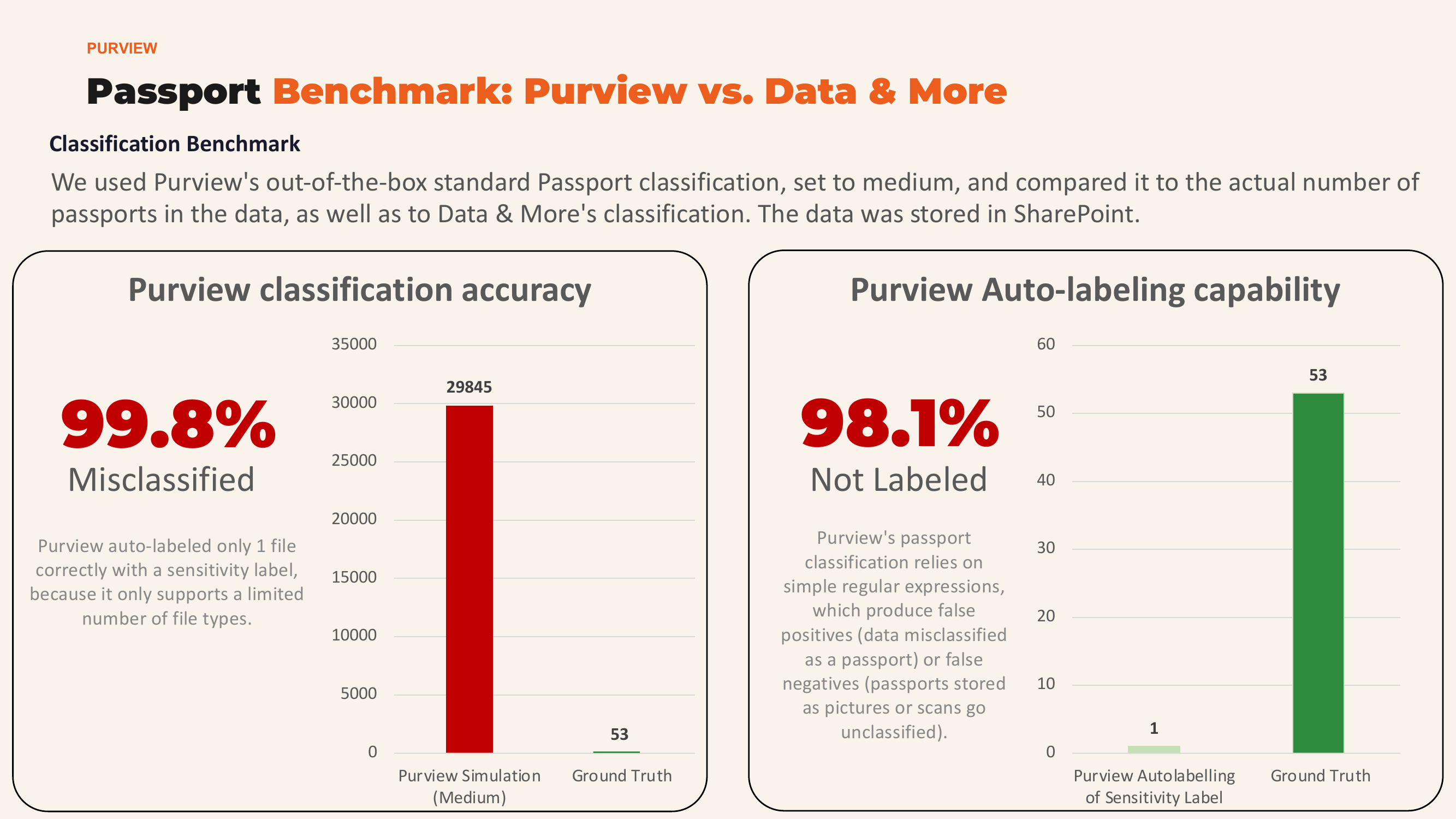
99.8% misclassified by Purview's classification. Purview relies on simple regular expressions, which produce false positives (data misclassified as a passport) and false negatives (passports stored as images or scans go undetected).
98.1% not labeled by Purview's auto-labeling. Only 1 file was correctly labeled with a sensitivity label, because Purview only supports a limited number of file types.
Benchmark Results: Payment Card Classification
For payment card data, the results were somewhat better but still alarming:
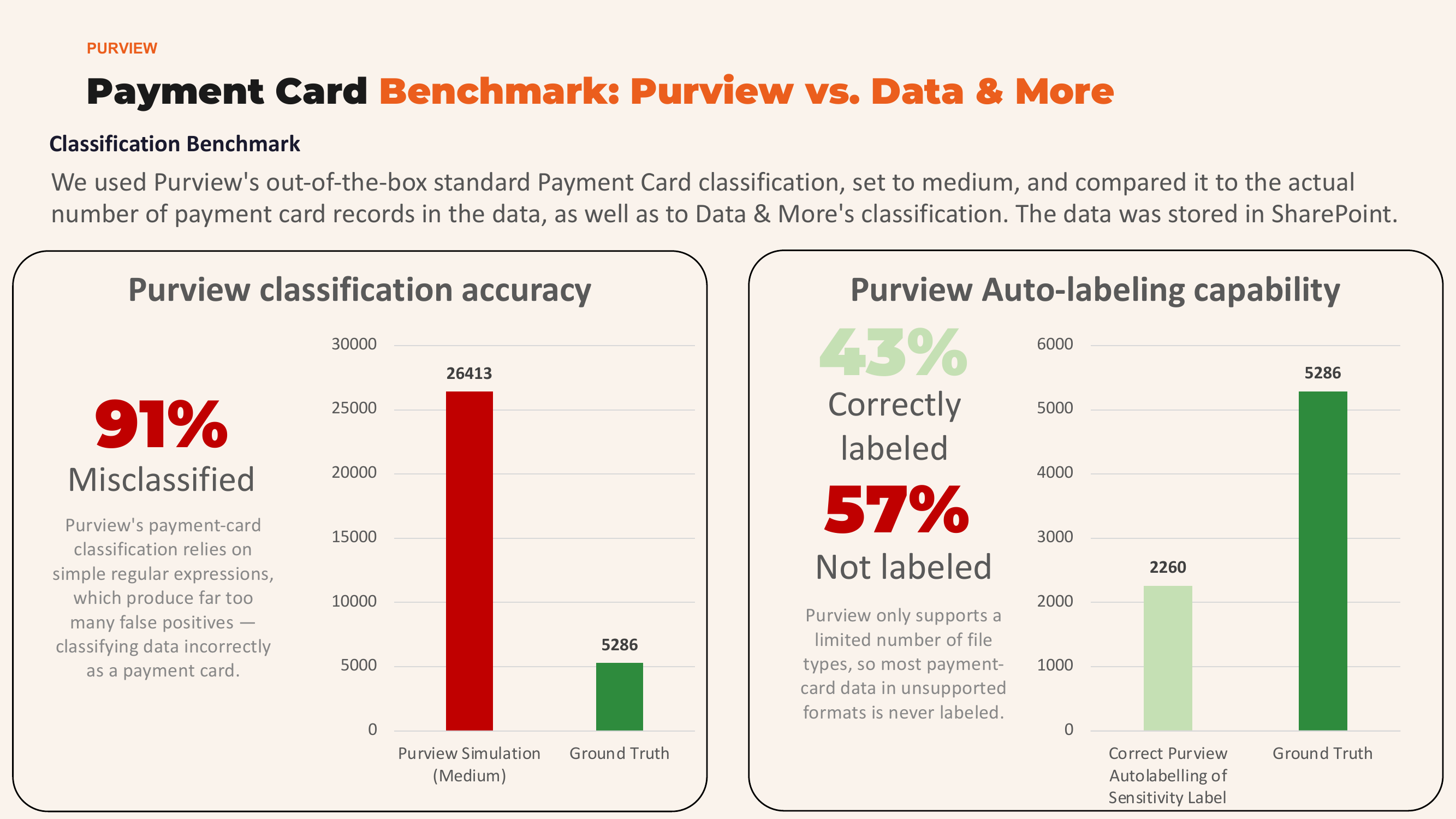
91% misclassified by Purview. The regex-based classification produces far too many false positives, incorrectly flagging data as payment cards.
57% not labeled by auto-labeling. Only 43% of payment card data was correctly labeled, because Purview only supports a limited number of file formats.
What Purview Is Missing for GDPR
Purview has no real or compliant GDPR/privacy classification. It offers only a few imprecise samples in a limited number of languages. To achieve actual GDPR compliance, organizations would need to custom-develop classification for 28+ languages across dozens of missing privacy categories.

Missing national certificates: Birth, citizenship, marriage, divorce, registered partnership, ancestry, name change, proof of citizenship, marital status, place of residence, religion, and more.
Missing privacy data types: Health information (medicine, diagnosis, illness), political orientation, sexual orientation, ethnic origin, trade union affiliation, religious orientation, personal tax information, salary information, employment contracts, recruitment data, CVs, written warnings, work absence, criminal records, written consents, travel information, photo geolocation, and more.
The Labeling Dilemma
Purview offers two labeling options, and both have fundamental limitations:

Manual labeling only works on new files, but 99.99% of data already exists. Research shows users dislike manual labeling and do not do it voluntarily. Studies show only 0.77% of data gets manually tagged. When users can only choose from 4-5 label options, the result is too limited for real compliance requirements.
Auto-labeling does not support emails at rest or their attachments, and only covers a limited number of file formats. In real-world environments, Purview auto-labeling supports around 5% of all unstructured data. The classification itself is not GDPR compliant, with a 50-99% error rate that creates systemic compliance and DLP exposure. There are also additional per-page costs for PDF and image OCR scanning on top of the E5 license.
Try It Yourself
Download the dataset from Hugging Face, load it into your own SharePoint or Exchange environment, and run Purview classification against it. Compare the results to the manually validated ground truth. We are confident you will see the same results.
If you want to see how Data & More classifies the same data, get in touch for a demo.
Data & More
Because you can't leak data that isn't there
